Техническое задание к коннектору
В платформе Yva.ai существует возможность загружать пользователей и разнообразные данные по ним из сторонних систем. Под сторонними системами подразумеваются различные корпоративные приложения, которые используют клиенты Yva.ai для своей работы, например: Bitrix, Telegram, Яндекс почта и др. Пользовательские данные могут быть самыми разными, как правило это: письма, сообщения, комментарии, реакции, звонки, задачи, встречи и т.д. На основе этих данных Yva.ai выявляет выгорающих сотрудников, их активность, длину рабочего дня, тональность писем и различные другие показатели. Клиенты Yva.ai могут самостоятельно грузить в нее данные, для этого им необходимо написать коннектор - ПО, которое будет производить сбор пользователей и пользовательских данных из сторонней системы и отправлять их в Yva.ai.
В данном документе представлены требования и рекомендации к работе коннектора для платформы Yva.ai, большая часть ТЗ - по сути описание опыта Yva.ai по разработке коннекторов, которым Вы можете воспользоваться. Коннектор может быть как частью сторонней системы, например плагин Bitrix, либо существовать отдельно от сторонней системы и общаться с ней через API. Так как данное ТЗ универсальное, то в нем будут рассматриваться в том числе ситуации, которые могут возникнуть при работе коннектора со сторонней системой через API, если Ваш коннектор является частью сторонней системы, то эта информация для Вас неактуальна. В ТЗ присутствуют блок-схемы алгоритмов. Обратитесь в поддержку, чтобы получить доступ к оригиналам блок-схем на draw.io.
Общие требования к коннектору
1. Необходимо создать новый источник API интеграции в интерфейсе платформы Yva.ai.
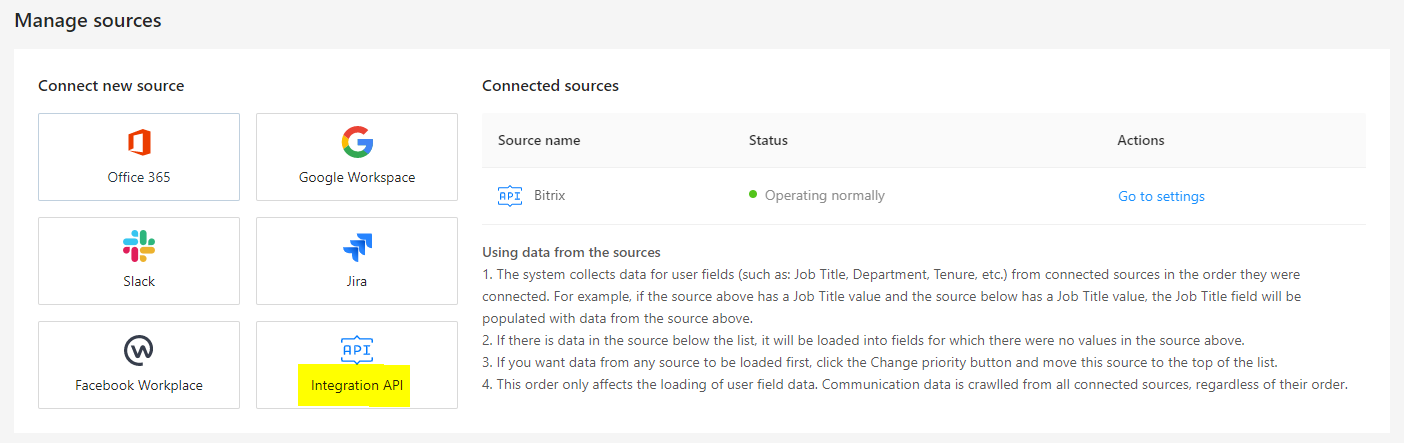
Сохраняем настройки для коннектора, предоставленные системой (конечные точки URL, токен доступа) в файл настроек. Ниже представлен скриншот данных настроек для коннектора с тестовой развертки;

2. Коннектор должен иметь файл настроек, в котором сохраняются все необходимые данные для работы коннектора. Файл должен иметь следующие параметры (ситуации, в которых данные параметры используются, описаны ниже):
Название | Описание | Обязательность | Значение по умолчанию |
UsersEndpointUrl | Конечная точка URL пользователей. Получается при создании источника | + | - |
MessagesEndpointUrl | Конечная точка URL сообщений. Получается при создании источника. Добавлять это поле, только если будут отправляться сообщения в Yva.ai. | - | - |
YvaAuthToken | Токен доступа к Yva.ai. Получается при создании источника. Использовать в хидере Authorize при каждом запросе | + | - |
MaxRequestSizeInMb | Максимальный размер тела запроса к Yva Integration API в мб | + | 8 мб |
MaxRequestSizeInUsers | Максимальное количество пользователей в запросе к Yva Integration API | + | 50 |
MaxRequestSizeInMessages | Максимальное количество сообщений в запросе к Yva Integration API. Добавлять это поле, только если будут отправляться сообщения в Yva.ai. | - | 100 |
GettingUsersSyncInterval | Периодичность получения пользователей из сторонней системы, сохранения/обновления их в БД коннектора и отправки их в Yva Integration API (т.е. периодичность для первого шедулера) | + | 1 раз в сутки |
GettingEnableUsersSyncInterval | Периодичность получения пользователей, у которых включен сбор данных, из Yva Integration API и обновления данных пользователей в БД (т.е. периодичность для второго шедулера) | + | 2 раза в сутки |
RequestDelay | Время задержки для повторения запроса к сторонней системе в случае ошибки. Добавлять это поле, только если коннектор отделен от сторонней системы. | - | 1 раз в час |
YvaRequestDelay | Время задержки для повторения запроса к Yva.ai в случае ошибки | + | 1 раз в час |
CrawlingDepthAt | Дата в прошлом, по которую (включительно) нужно грузить данные. Данное поле изменяется только из кода. | + | 1 год в прошлое |
3. Все ошибки и основные действия коннектора должны логироваться. При написании кода для обработки ошибок от стороннего API, необходимо изучить его документацию, так как политика работы с ошибками может отличаться у разных API, следовательно подходы к обработке данных ошибок тоже должны различаться. В целом политика обработки ошибок в коннекторе должна быть такой:
Основные действия необходимо логировать с уровнем INFO, ошибки - с уровнем ERROR или FATAL;
В случае возникновения ошибок во время запроса к Yva Integration API или API/DB сторонней системы, ошибку с информацией о запросе необходимо логировать с уровнем ERROR и, если ошибка временная (например таймаут, временные неполадки сервера, Too Many Requests и т.д.), то необходимо повторять запрос с установленным в настройках интервалом (delay параметры). Если же ошибка более серьезная (например неверный запрос), то следует пропустить данный запрос;
Если произошла непоправимая ошибка при работе коннектора, нарушающая его работу, необходимо логировать ее с уровнем FATAL;
В лог нужно писать дату, когда произошла ошибка, место, stackTrace, запрос, код ошибки. Всю ту информацию, которая показывает когда, где, при каких обстоятельствах произошла данная ошибка. Если лог с уровнем INFO, то необходимо указать дату, место, строку, которая даст понять что произошло;
Время жизни лога - 1 месяц;
У администратора сторонней системы должен быть доступ к логам, чтобы при необходимости их можно было использовать для выявления причин возникших проблем.
4. Если коннектор не является частью сторонней системы, то по возможности для доступа к ней нужно использовать протокол OAuth 2.0, все данные для авторизации должны безопасно храниться;
5. Код коннектора должен соответствовать лучшим практикам и быть адекватно покрыт комментариями;
6. Для доступа к Yva Integration API использовать токен доступа из файла настроек и URLs, полученные в 1 пункте. Пока токен не обновляется, но в будущем планируется это исправить;
7. При разработке коннектора необходимо учитывать какие объемы данных он должен будет обрабатывать и за какой срок и соответствующим образом оптимизировать код, работу со сторонними API, БД, проставить нужные значения параметров в файле настроек;
8. Количество одновременно отправляемых в Yva Integvration API запросов должно не превышать 20;
9. Для коннектора важно проводить не только функциональное, но и нагрузочное тестирование, особенно если он работает с большими объемами данных;
10. Для каждого алгоритма, описанного в данном ТЗ, действует правило: в случае возникновения ошибки при получении пользователей из сторонней системы, отправке или получении пользователей из Yva.ai, отправке данных в Yva.ai, сохранении/обновлении этих пользователей или их данных в БД коннектора, необходимо записать ее в лог с уровнем ERROR и, если ошибка “временная”, повторять попытку через установленный промежуток времени (повторять не с начала, а с момента, когда возникла ошибка) и пытаться, пока не получится выполнить операцию. Если же ошибка “постоянная” - пропустить запрос. Более подробно политика работы с ошибками описана в 3 пункте общих рекомендаций. Данные алгоритмы являются рекомендацией, основанной на опыте разработки коннекторов для Yva.ai. При нахождении неточностей/ошибок/проблем в алгоритмах, а также при возникновении идей по улучшению данных алгоритмов или вопросов стоит обращаться к сотрудникам Yva.ai.
Требования и рекомендации по загрузке пользователей
В первую очередь для работы коннектора необходимо получить пользователей, для которых мы будем собирать различные данные (сообщения, задачи, звонки и т.д.). Алгоритм работы с пользователями коротко можно описать так: пользователи грузятся из сторонней системы и отправляются в Yva Integration API, далее в Yva.ai выбираются пользователи, для которых будут собираться данные. После этого коннектор получит выбранных пользователей и начнет сбор данных для них. Более подробное описание данного функционала приведено ниже.
Для загрузки пользователей запускаем шедулер, который с установленной периодичностью получает пользователей из сторонней системы (параметр GettingUsersSyncInterval);
При получении ошибки во время запроса к API/DB сторонней системы, ее необходимо логировать, а сам запрос повторить через время, установленное в файле настроек (параметр RequestDelay) или пропустить, в зависимости от ошибки (см. пункт 3 в общих рекомендациях). Количество попыток бесконечно, в случае повторения;
Сохраняем/обновляем информацию по пользователям в локальной БД коннектора, на основе данных, полученных из сторонней системы, включая активность (поле bool isActive). В данном случае интересует именно рабочая активность (пишет ли пользователь рабочие письма, сообщения, осуществляет звонки и т.д.). Если сторонняя система больше не возвращает конкретного пользователя, проставляем для него isActive = false. Если пользователь был помечен, как уволенный/в декрете/и т.д., но потом снова стал активен, обновить isActive в локальной БД;
После получения пользователей из сторонней системы и сохранения/обновления их в БД, их следует отправить в Yva Integration API. Отправление должно проходить батчами с установленной периодичностью (параметр GettingUsersSyncInterval). Размер батча также устанавливается в файле настроек, по умолчанию размер тела запроса должен не превышать 8 мб, при этом в запросе должно быть не более 50 пользователей (параметры MaxRequestSizeInMb и MaxRequestSizeInUsers). В Yva Integration API необходимо слать только активных пользователей. Политика обработки ошибок аналогична той, что описана для работы в 3 пункте общих рекомендаций, в случае повторения запроса использовать параметр YvaRequestDelay;
Для отправки пользователей в Yva Integration API
использовать POST /api/integration/2.0/sources/users
Коды ответов:
2XX - ок
4XX - запрос не повторяем (пропускаем батч), повторяем запрос для 408, 429
5XX - запрос не повторяем (пропускаем батч), повторяем запрос для 503, 504, 524Формат отправляемых данных:
{ "sourceType": "Bitrix", "users": [ { … } ] }CODE
Пользователь имеет обязательные и необязательные поля. Стоит подчеркнуть, что многие поля хоть и являются необязательными, но все же очень желательно передавать по ним данные, так как часто по этим полям идет фильтрация, дополнительная аналитика и т.д., также они регистронезависимы.
Поля, которые следует слать в данном запросе:
Название | Описание | Обязательность | Тип данных | Комментарий |
SourceType | Определяет тип источника | - | string | Определяет тип источника. Например “Bitrix” |
Объект User - обязательный, users[] | ||||
Id | Id пользователя в системе-источнике | - | string | - |
PrimaryEmail | Email пользователя | + | string | - |
Identities | Массив объектов, идентифицирующих пользователя | + | object[] | В каждом объекте 2 поля: type (Email/ActiveDirectory/Telegram/Custom) и value "identities": [{"type": "email","value": "email@gmail.com"}]. PrimaryEmail должен входить в Identities. |
FirstName | Имя | - | string | Не пустое, если не null. |
LastName | Фамилия | - | string | Не пустое, если не null. |
DisplayName | Отображаемое имя | - | string | Не пустое, если не null. |
Department | Департамент | - | string | Не пустое, если не null. |
JobTitle | Должность | - | string | Не пустое, если не null. |
ManagerEmail | Email руководителя | - | string | Не пустое, если не null. |
BirthDate | Дата рождения | - | date | - |
Gender | Пол | - | string | Значение должно быть null или Female/Male/NonBinary |
HireDate | Дата приема на работу | - | date | - |
TerminationDate | Дата увольнения | - | date | - |
EmploymentType | Тип занятости | - | string | Значение должно быть null или FullTime/PartTime/Contract/Outsource |
RemoteWork | Работает ли пользователь удаленно | - | bool | - |
ManagementLevel | Уровень менеджмента | - | string | Не пустое, если не null |
PotentialEvaluation | Оценка потенциала | - | string | Не пустое, если не null |
PerformanceLevel | Уровень перфоманса | - | string | Не пустое, если не null |
Location | Место жительства | - | string | Не пустое, если не null |
Запускаем шедулер, который с установленной периодичностью (параметр GettingEnableUsersSyncInterval) получает из Yva пользователей, для которых включен сбор данных. Для этих пользователей в дальнейшем будут грузиться сообщения, задачи, звонки и т.д.
Использовать GET /api/integration/2.0/sources/users
Коды ответов:
2XX - ок
4XX - запрос не повторяем (пропускаем батч), повторяем запрос для 408, 429
5XX - запрос не повторяем (пропускаем батч), повторяем запрос для 503, 504, 524
Формат возвращаемых данных:[ { "id": "string", //Id пользователя в сторонней системе или его email из поля PrimaryEmail (смотри таблицу выше) "displayName": "string", //отображаемое в Yva.ai имя пользователя (как правило ФИО) "emails": "string[]" //на деле пока тут будет только 1 email } ]CODEПри получении ошибки во время запроса к Yva.ai, ее необходимо логировать, а сам запрос повторить через время, установленное в файле настроек (параметр YvaRequestDelay) или пропустить, в зависимости от кода ошибки (см. предыдущий пункт и политику обработки ошибок в 3 пункте общих рекомендаций). Количество попыток бесконечно, в случае повторения;
На основе вернувшихся из Yva.ai пользователей, обновляем поле bool isEnabled для соответствующих пользователей в БД коннектора (включен ли для них сбор данных). Ищем их для обновления с помощью полученного Id или Email. От того включен ли пользователь зависит будут собираться по нему данные или нет;
Алгоритмы для загрузки пользователей
Ниже представлены рекомендуемые алгоритмы работы шедулеров для получения и обновления пользователей.
Загрузка данных в Yva.ai
Требования по загрузке данных в Yva.ai
В платформу Yva.ai можно грузить самые разные данные, это могут быть сообщения, комментарии, реакции, задачи, события и т.д. При наличии пользователей, для которых включен сбор данных, следует инициировать загрузку данных для них (синхронизацию пользователей). Загрузка данных в Yva Integration API должна удовлетворять следующим требованиям:
Первичная синхронизация должна проходить от текущего момента, до установленной даты в прошлом (т.е. данные должны грузиться до определенной глубины краулинга). Глубину краулинга нужно получить из Yva Integration API, используя следующий метод:
GET /api/integration/2.0/sources/settings
Коды ответов:
2XX - ок, если ответ не null (если получили null, то считаем это ошибкой, связанной с запросом и больше данный запрос не повторяем)
4XX - запрос не повторяем (пропускаем батч), кроме 408, 429
5XX - запрос не повторяем (пропускаем батч), кроме 503, 504, 524
Политику обработки ошибок можно посмотреть в 3 пункте общих рекомендаций.Формат возвращаемых данных:
[ { "crawlingDepthAt": "date" //глубина краулинга, т.е. дата в прошлом, до которой (включительно) загружаем данные по пользователю (обычно, при сборе данных, смотрится дата создания Activity) } ]CODEПосле первичной синхронизации необходимо с настраиваемой частотой подгружать новые данные по пользователю (т.е. должен идти обычный краулинг);
Отправка данных в Yva Integration API должна проходить батчами. Размер тела запроса в Yva должен не превышать 8 мб (параметр MaxRequestSizeInMb), при этом в запросе должно быть не больше данных, чем указано в соответствующей константе в файле настроек (параметр MaxRequestSizeInMessages/MaxRequestSizeInEvents/MaxRequestSizeInTasks ...);
Количество одновременных запросов в Yva Integration API не должно превышать 20;
Глубина краулинга может увеличиваться, в таком случае необходимо догружать данные от старой глубины до новой (делать экстра-краулинг) и уметь делать это одновременно с обычным краулингом. Глубина краулинга не должна уменьшаться;
Если для пользователя отключить сбор данных, то необходимо больше не грузить данные по нему. Если включить, то отправку данных нужно возобновить;
Загрузка должна идти от новых данных к старым;
Получение данных из сторонней системы должно идти фоном и не нагружать ее, не влиять на качество ее работы;
При получении ошибок во время запроса к API/DB сторонней системы, ее необходимо логировать, а сам запрос повторить через время, установленное в файле настроек (параметр RequestDelay) или пропустить, в зависимости от кода ошибки (см. пункт 3 в общих рекомендациях). Количество попыток бесконечно, в случае повторения. Аналогично поступаем и при запросах к Yva Integration Api, только вместо параметра RequestDelay, используем YvaRequestDelay;
Необходимо стремиться к тому, чтобы в случае прерывания краулинга, после его возобновления, краулинг продолжился с того места, на котором остановился в прошлый раз. При этом необходимо не потерять данные, но стараться максимально сократить число возможных дублей.
Рекомендации по загрузке данных в Yva.ai из сторонней системы
В текущей главе приведены примеры алгоритмов для загрузки данных в Yva.ai, алгоритмы основаны на опыте работы с различными коннекторами. Данным опытом можно воспользоваться при разработке своих алгоритмов для коннектора. Для удобства тип данных пользователя, абстрактная “активность” в приведенных алгоритмах, будет называться Activity, на практике это будет: Message, Reaction, Task, Event и т.д.
Для каждого типа Activity запущены 2 шедулера:
Первый будет проводить первичную загрузку данных (сообщения/комментарии/реакции/задачи и т.д.) для выбранных пользователей от текущего момента до установленной глубины в прошлом, а затем с установленной периодичностью догружать свежие данные;
Второй шедулер будет сохранять актуальную глубину краулинга и собирать данные в случае ее изменения.
Оба шедулера должны собирать данные и отправлять их в Yva.ai с заданной в файле настроек периодичностью, т.е. синхронизировать пользователей;
В файл настроек коннектора для каждого шедулера Activities (речь о первом шедулере, который будет делать инициализацию и сбор свежих данных) необходимо добавить объект CrawlerSchedullerSettings, ниже в таблице приведено описание полей данного объекта. Ситуации, в которых данные параметры используются, описаны ниже.
Название | Описание |
CrawlerSchedullerSettings.ActivityTriggerInterval | Периодичность поиска в БД коннектора пользователей, для которых в Yva.ai проставлен сбор данных и для которых при этом пришло время обновления (принцип отбора пользователей для обновления описан ниже) |
CrawlerSchedullerSettings.ActivitySyncInterval | Частота синхронизации Activity для каждого отдельного пользователя |
CrawlerSchedullerSettings.Limit | Количество пользователей, которые одновременно синхронизируются |
Для работы первого шедулера, в локальной БД коннектора, для каждого пользователя, предусмотрены следующие поля:
Название | Описание |
Bool isEnabled | Включен ли сбор данных для пользователя? |
Date LastSyncUpdateAt | Дата последней загрузки activities (синхронизации) пользователя, не обязательно полной |
Date InitSyncFinishAt | Дата, когда была полностью завершена первичная инициализация пользователя |
Date LastSyncActivityCreatedAt | Дата создания последней загруженной в Yva.ai Activity |
Date SyncDepthAt | Дата создания первой Activity, отправленной на предыдущей синхронизации пользователя. |
Также для загрузки данных для каждого пользователя создается объект SyncState, который имеет следующие поля:
Название | Описание |
Date StartSyncAt | Дата, начиная с которой включительно грузятся activities |
Date EndSyncAt | Дата, по которую включительно грузятся activities |
Int Skip | Сколько activities пропустить |
Int Take | Сколько activities взять на обработку |
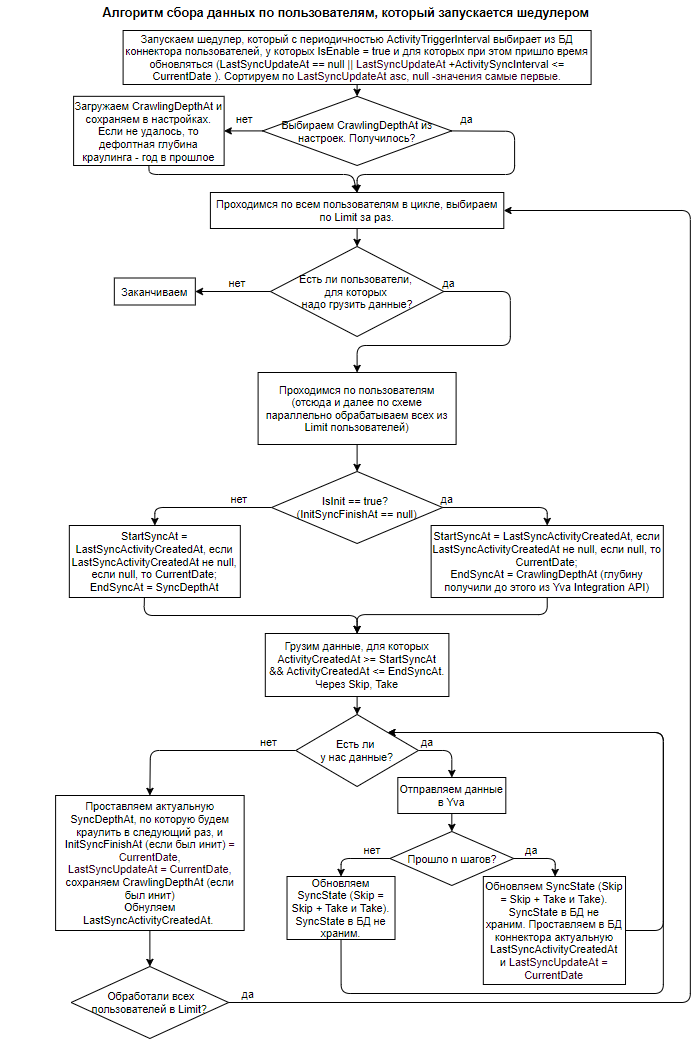
Далее приведена схема алгоритма для первичной загрузки данных в Yva Integration API и для подгрузки новых данных, после первичной загрузки: https://app.diagrams.net/#G1inN8NPl29mq5s8B7NadHQn8CmWxGWc7U
Также в файл настроек коннектора для каждого шедулера Activities, который будет обновлять глубину краулинга и проводить загрузку данных, в случае ее изменения (проводить докраулинг/экстра-краулинг), необходимо добавить объект ExtraSchedullerSettings, ниже в таблице приведено описание полей данного объекта.
Название | Описание |
ExtraSchedullerSettings.ActivityTriggerInterval | Периодичность получения и сохранения/обновления актуальной глубины краулинга из Yva Integration API и запуска докраулинга, в случае ее изменения |
ExtraSchedullerSettings.ActivitySyncInterval | Частота докраулинга Activities для каждого отдельного пользователя. Значение должно быть не менее 1 часа |
ExtraSchedullerSettings.Limit | Количество пользователей, которые одновременно синхронизируются |
Для работы второго шедулера, в локальной БД коннектора, для каждого пользователя, предусмотрены следующие поля:
Название | Описание |
Date LastExtraSyncUpdateAt | Дата последней загрузки activities (синхронизации) пользователя. Речь о докраулинге. |
Date LastExtraSyncActivityCreatedAt | Дата создания последней загруженной во время докраулинга в Yva.ai Activity |
Date CrawlingDepthAt | Глубина, до которой синхронизирован пользователь |
Date OldCrawlingDepthAt | Можно добавить старую глубину, до которой ранее синхронизировались данные пользователя |
Для загрузки данных для каждого пользователя в случае изменения глубины краулинга создается объект ExtraSyncState, который имеет следующие поля:
Название | Описание |
Date StartExtraSyncAt | Дата, начиная с которой включительно грузятся activities |
Date EndExtraSyncAt | Дата, по которую включительно грузятся activities |
Int Skip | Сколько activities пропустить |
Int Take | Сколько activities взять на обработку |
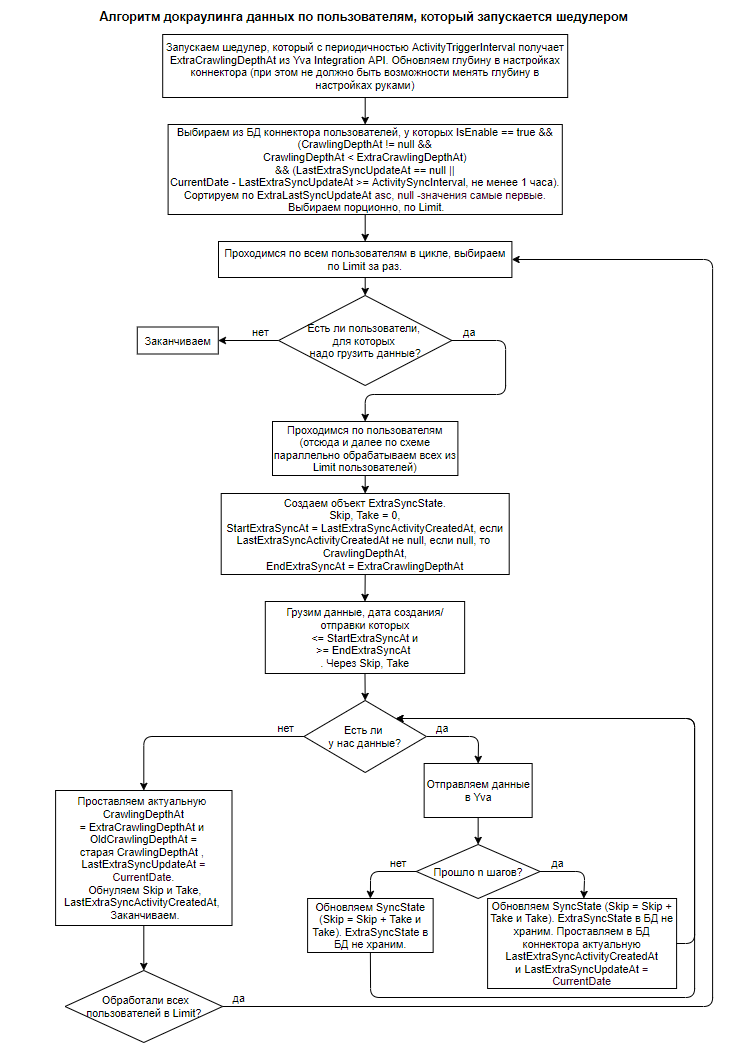
Далее приведена схема алгоритма для загрузки данных в Yva Integration API в случае изменения глубины краулинга: https://app.diagrams.net/#G10kLcV7ZvUhWwMCodq5sda1HiQnOkvYfc
Сообщения
В данном разделе будет подробно разобрана сущность Сообщение. К данной сущности можно причислить сообщение/комментарий в чате/беседе/канале/сообществе. Сбор сообщений очень важен для построения кругов сотрудничества пользователей, определения их выгорания и т.д.
При загрузке сообщений в Yva Integration API, передаются следующие поля:
Название | Описание | Обязательность | Тип данных | Комментарий |
EventId | Уникальное Id сообщения в системе-источнике | + | string | - |
EventDate | Дата отправки сообщения | + | ISO date | Должно передаваться в UTC-формате |
Identities | Массив объектов, идентифицирующих пользователя | + | object[] | Данное поле необходимо для того, чтобы идентифицировать пользователя, отправившего сообщения. Т.е. в массиве Identities должны содержаться identities пользователя, которые мы отправляли при загрузке самих пользователей в Yva.ai. "identities": [{"type": "email","value": "email@gmail.com"}]. |
ThreadId | Если в системе-источнике есть треды, то в данном поле должно быть Id первого сообщения в треде | - | string | Важное поле, по нему вычисляется время ответа, связь с другими активити |
Text | Текст | - | string | Текст сообщения |
Объект Link - необязательное поле, links[] | ||||
UserId | Email связанного пользователя | + | string | Писать сюда email пользователей из приватных чатов, если чаты публичные, то писать сюда упоминаемых в сообщении пользователей. Это поле нужно для связки с ранее переданными в Yva.ai пользователями. (Связка идет через Identities) |
UserSeverity | Важность пользователя | - | string | Передавать High для упоминаний в чатах, Low для участников чата. |
Объект Payload - необязательное поле, object | ||||
EventType | Тип активити | + | string | Значение должно быть PrivateMessage/PublicMessage и т.д. Для сообщений из приватных чатов - PrivateMessage, из публичных - PublicMessage |
SourceType | Определяет тип источника | - | string | Определяет тип источника. Например “Bitrix” |
Дополнительные специфические поля активити, далее в таблице указаны поля сущности “сообщение” | ||||
SharedMessageId | Id пересланного сообщения | - | string | Не пустое, если не null. |
Channel | Канал, в котором опубликовано сообщение | + | object | Это может быть канал, чат, беседа, сообщество и т.д. |
Channel.Id | Id канала | + | string | - |
Channel.Name | Название канала | - | string | - |
Для загрузки сообщений в Yva Integration API необходимо использовать следующий метод:
POST /api/integration/2.1/activity
Коды ответов:
2XX - ок
4XX - запрос не повторяем (пропускаем батч), кроме 408, 429
5XX - запрос не повторяем (пропускаем батч), кроме 503, 504, 524
Политику обработки ошибок можно посмотреть в 3 пункте общих рекомендаций.
Формат отправляемых данных:
[
{
"eventId": "54g45g54h65h65hj65j6",
"eventDate": "2021-08-10T12:01:13.826Z",
"identities": [
{
"type": "email",
"value": "email@jwsh.qqm"
},
{
"type": "Telegram",
"value": "g43g43g43"
}
],
"threadId": "12",
"links": [
{
"userId": "61137d4f416a58dcae8cb36f",
"userSeverity": "high"
}
],
"text": "text",
"payload": {
"eventType": "PrivateMessage",
"sourceType": "Bitrix",
"sharedMessageId" : "123",
"Channel" : {
"Id" : "1",
"Name" : "channel"
}
}
}
]
Размер тела запроса в Yva.ai должен не превышать 8 мб, при этом в запросе должно быть не более 100 сообщений (параметры MaxRequestSizeInMb и MaxRequestSizeInMessages);